


 Review Article
Review Article
Tensor Formulation of the General Linear Model with Einstein Notation
Received Date: August 24, 2023; Published Date: August 29, 2023
Abstract
The general linear model is a universally accepted method to conduct and test multiple linear regression models. Using this model, one has the ability to simultaneously regress covariates among different groups of data. Moreover, there are hundreds of applications and statistical tests associated with the general linear model.
However, the conventional matrix formulation is relatively inelegant which yields multiple difficulties including slow computation speed due to a large number of computations, increased memory usage due to needlessly large data structures, and organizational inconsistency. This is due to the fundamental incongruence between the degrees of freedom of the information the data structures in the conventional formulation of the general linear model are intended to represent and the rank of the data structures themselves.
Presented here is an elegant reformulation of the general linear model which involves the use of tensors and multidimensional arrays as opposed to exclusively flat structures in the conventional formulation. To demonstrate the efficacy of this approach, a few common applications of the general linear model are translated from the conventional formulation to the tensor formulation.
Keywords:General Liner Model, Tensor, Multidimensional Array, Computational Efficiency, Einstein Notation, Matrix Formulation, Statistical Tests, Parameters
Introduction
The general linear model (GLM) or general multivariate regression model is a widely accepted technique across multiple fields to perform several multiple linear regression models. It offers advantages such as the ability to simultaneously regress covariates among different groups of data, among others. The applications and statistical tests derived from and expressed using the conventional matrix formulation of the GLM are numerous and multifaceted [1,2].
However, the conventional matrix formulation is relatively inelegant in some embodiments, yielding compromised computational efficiency and increased order of complexity in automation of statistical tests. For example, in cases in which multiple groups are modeled, the matrix formulation lacks the dimensionality to encode the relevant linear coefficients and variables. The brute force solution to this in the conventional formulation is to simply stagger the indices corresponding to the various groups such that the relevant parameters and variables are all encoded in a sparse, flat data structure.
Put forth here is an elegant reformulation of the GLM, such that the data structures describing the important parameters and variables are tensors represented in Einstein notation [3]. To demonstrate the efficacy of this approach, a general description of the formulation will precede a few brief examples of applications for which this formulation is more elegant than the matrix formulation.
Conventional Formulation of the GLM
The GLM most generally consists of N domain variables from which a linear atlas is generated which maps this domain space of 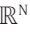 to a linear manifold in
to a linear manifold in 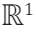 defined by an outcome variable. Moreover, the parameters defining such atlas depend on the group from which the domain variables are derived. This linear atlas is conventionally expressed as described in Eq. 1.
defined by an outcome variable. Moreover, the parameters defining such atlas depend on the group from which the domain variables are derived. This linear atlas is conventionally expressed as described in Eq. 1.

Where y is the outcome variable, X is the covariant vector consisting of the domain variables with the first entry equal to one corresponding to the intercept, and 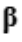 is the contravariant vector
consisting of the coefficients of said domain variables. This map is generated with a function of a series of residuals defined in Eq. 2.
is the contravariant vector
consisting of the coefficients of said domain variables. This map is generated with a function of a series of residuals defined in Eq. 2.

In this, Y is the contravariant vector representing samples of the linear outcome manifold in  for a particular group, while X is a matrix describing a series of the same covariant vectors in Eq. 1,which were experimentally determined to map to said samples of the outcome manifold. By choosing the parameters of
for a particular group, while X is a matrix describing a series of the same covariant vectors in Eq. 1,which were experimentally determined to map to said samples of the outcome manifold. By choosing the parameters of 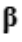 the linear map will, at best, approximate the experimentally defined atlas, im-plying the existence of residuals N
the linear map will, at best, approximate the experimentally defined atlas, im-plying the existence of residuals N
The matrices are written out explicitly for only one regressor or domain variable in Eq. 3.

At this point, the model is inconspicuously inelegant. However,upon the introduction of numerous groups from which the experi-mental data is sampled, it becomes evident. Expanding this exam-ple to one regressor in two groups is shown in Eq. 4.

Clearly in this staggered configuration, as more groups are in-troduced into the model, the matrix continues to grow, with the majority of entries being equal to zero, which yields an unneces-sarily large number of computations and quantity of memory us-age. Moreover, without a priori knowledge of both the number of groups and number of regressors, it is impossible to predict the organizational structure of the matrix. In general, a model with m
regressors, n groups, and k data points in each group will require a matrix X as a series of 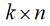 covariant vectors, each with n indices encoding only 1s and 0s which are implicated as coefficients of the intercepts and
covariant vectors, each with n indices encoding only 1s and 0s which are implicated as coefficients of the intercepts and 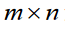 indices encoding the experimental indepen-dent data. The resultant size of the data structure in question is then
indices encoding the experimental indepen-dent data. The resultant size of the data structure in question is then  .
.
Tensor Formulation of the GLM
These problems are circumvented with an alternative tensor formulation of the model expressed in Einstein notation. Notably, Eq. 2 Can be written as Eq. 5.

Here, k indexes the samples of the experimental mapping, 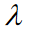 indexes over the group, and
indexes over the group, and 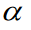 indexes over the intercept and each regression variable or parameter. From this, the extension to the translation of Eq. 1 is trivial. An example of such formulation in hybrid matrix Einstein notation with one regression parameter is
shown in Eq. 6.
indexes over the intercept and each regression variable or parameter. From this, the extension to the translation of Eq. 1 is trivial. An example of such formulation in hybrid matrix Einstein notation with one regression parameter is
shown in Eq. 6.

GLM Contrast Matrix in Tensor Notation
The null hypothesis 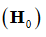 statements to test in the GLM take the form of a linear combination of the atlas parameters in
statements to test in the GLM take the form of a linear combination of the atlas parameters in 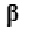 is equal to 0. This linear combination is conventionally expressed in a manner outlined in Eq.7.
is equal to 0. This linear combination is conventionally expressed in a manner outlined in Eq.7.

Where, g corresponds to the value 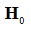 asserts is equal to zero
and C is the GLM contrast matrix, which is a covariant vector with
indices corresponding to the atlas parameters in
asserts is equal to zero
and C is the GLM contrast matrix, which is a covariant vector with
indices corresponding to the atlas parameters in 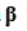 which serves as
their linear coefficients in the
which serves as
their linear coefficients in the 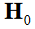 This is expressed ex-
plicitly for 2 hypotheses
This is expressed ex-
plicitly for 2 hypotheses 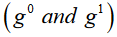 ,one regressor, and two groups
in Eq. 8.
,one regressor, and two groups
in Eq. 8.

Of note, even though, as it is shown here, the conventional for-mulation is compatible with multiple hypothesis testing, it has not been conventionally implemented in this way and each row of the vector g and matrix C are implemented as separate statements. The compatible expression in the tensor formulation is shown in Eq. 9.

This model is more naturally compatible with multiple 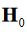 which
which 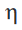 indexes over, for F-testing or multiple t-tests.
indexes over, for F-testing or multiple t-tests.
An example of such expression with two 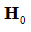 statements in a
model with two separate groups and a single regressor is outlined component-wise in Eq. 10-23.
statements in a
model with two separate groups and a single regressor is outlined component-wise in Eq. 10-23.








While the number of elements in this expression remains un-changed in the reformulated version, the rank of the data structures are congruent with their degrees of freedom. Moreover, translating this expression is necessary to implement applications which use it and would benefit both from a computational speed and memory requirement perspective from the reformulation, such as the multi-ple t-tests application outlined below.
GLM Multiple T-Test in Tensor Notation
The justification for representing the various applications of the GLM in a tensor formulation is self-evident at this point, and in most cases it is straightforward to infer such representations from the conventional notation. However, this is not always true, espe-cially in embodiments which require inverting matrices.
The t-statistic is of the most important of these embodiments,which is represented in the conventional matrix notation in Eq. 24.

Where the t-statistic is generated separately for each 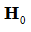 and
and 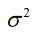 is the variance of the experimental outcome measure in most cases.
is the variance of the experimental outcome measure in most cases.
To express this in the tensor formulation, it is evident that the numerator is g, which is indexed for each hypothesis and, conse- quently, so is t. Moreover, it is clear that contracting a matrix with its transposed self can be expressed as shown in Eq. 25.

Moreover, the inverse of a matrix expressed in tensor notation is computed as Dr. Roger Penrose puts forth [4] and as is shown in Eq. 26.

Where 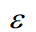 is the totally antisymmetric Levi-Civita symbol which is defined from the sign by the permutation of its indices such that
each value is a power of (-1) which matches the parity of the per-mutation, otherwise the value is zero. It is important to note that this is a general algorithm to invert tensors which scales in num-ber of computations with the number of elements in said tensor,regardless of rank. Therefore, a tensor of rank 2 (e.g. X in the con-ventional formulation) would require more computations to invert than a rank 3 tensor that has fewer data elements
is the totally antisymmetric Levi-Civita symbol which is defined from the sign by the permutation of its indices such that
each value is a power of (-1) which matches the parity of the per-mutation, otherwise the value is zero. It is important to note that this is a general algorithm to invert tensors which scales in num-ber of computations with the number of elements in said tensor,regardless of rank. Therefore, a tensor of rank 2 (e.g. X in the con-ventional formulation) would require more computations to invert than a rank 3 tensor that has fewer data elements 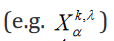 in the novel formulation). Extending this algorithm to
in the novel formulation). Extending this algorithm to 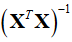 yields Eq.
27.
yields Eq.
27.


Results and Discussion
The tensor formulation of the GLM drastically decreases the number of elements in the data structures and reduces the quan-tity of operations required to perform computations with said data structures, especially as more groups, regressors, and hypotheses are incorporated in the model. Specifically, a model which would require  elements in the matrix X in the conventional formulation now only requires knm elements in the correspond-ing reformulated data structure, thereby reducing the number of elements by a factor of
elements in the matrix X in the conventional formulation now only requires knm elements in the correspond-ing reformulated data structure, thereby reducing the number of elements by a factor of 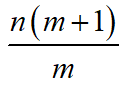 Depending on the data type used
in the implementation, this formulation can significantly improvethe memory required to store large data structures. Moreover, as the number of operations to perform a function scale with the size of a data structure this has the potential to significantly reduce the time required to test various hypotheses. Since the vast majority of
the applications of the GLM require computations with the matrix X, these improvements are ubiquitous among them.
Depending on the data type used
in the implementation, this formulation can significantly improvethe memory required to store large data structures. Moreover, as the number of operations to perform a function scale with the size of a data structure this has the potential to significantly reduce the time required to test various hypotheses. Since the vast majority of
the applications of the GLM require computations with the matrix X, these improvements are ubiquitous among them.
Additionally, the automation of hypothesis testing with the GLM is significantly simplified in the tensor formulation by the property that no a priori knowledge of the number groups, regressors, and hypotheses is needed to infer the structural organization of the data.
Finally, this solution is simply more elegant, as the rank of the tensors is complementary to the degrees of freedom of the infor-mation which the data structure in the GLM is designed to interact with.
There are hundreds of unique applications of the GLM, each of which can be formulated in this proposed manner. Presented here are the general structures of such formulations with a few exam-ples, but the literature would benefit from further translation of other applications.
Acknowledgement
None
conflict of Interest
None
References
- Khuri A, Mukherjee B, Sinha B, Malay Ghosh (2006) Design Issues for Generalized Linear Models: A Review. Statistical Science 21(3): 376-399.
- Peter Mc Cullagh (1984) Generalized linear models. European Journal of Operational Research 16(3): 285-292.
- Ahlander K (2002) Einstein summation for multidimensional arrays, Computers & Mathematics with Applications 44(8-9): 1007-1017.
- Roger P (1971) Applications of Negative Dimensional Tensors. In D.J.A. Welsh (Ed.), Combinatorial Mathematics and Its Applications pp. 221-224.
-

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.


